This blog post talks about using Terraform workspaces as a mechanism to maintain consistent environments across multiple cloud regions. While the examples in the post are AWS-centric, the concepts highlighted here are really cloud agnostic.
Short intro to Terraform State & Workspaces
For Terraform to be able to map resources in your config files to resources that have been provisioned in AWS or any other provider, it maintains a sort of lookup table in the form of the “Terraform State”. For example, if you were to have the following in your tf project
Within a Terraform state, there can only be one resource for a given name. In it’s simplest form, if I wanted to create many instances of resources like S3 buckets, for example, I would define multiple resources in my terraform config - one per resource. This becomes a bit tedious (not to mention a big violation of the DRY principle) when all the resources are exactly the same in terms of configuration except for, perhaps, its name. This is especially true for services like AWS API Gateway where Terraform configs requires at least 5-6 resources to be defined for even a simplistic “Hello World” type scenario.
Terraform workspaces (previously referred to as Terraform environments), is a way to address this concern with repetitive configurations. It is essentially a mechanism to partition the Terraform state so that many instances to the same resource can exists within it. The most commonly stated use case for this is to define a resource like an ec2 instance or a load balancer once per SDLC environment - in other words, define the resource once but terraform apply using the same configuration separately for “dev”, “qa”, and “prod” environments. This same capability can also be used to manage multi-region deployments.
The case for multi-region Deployments
Before we talk about how Terraform workspaces can solve for multi-region deployments, I do want to take a moment to talk about “why” we want to have multi-region deployments. It comes down to
You have a desire to insulate yourself against the failure of an entire cloud region. While unlikely, we have seen occurrences where an entire AWS cloud region (comprised to multiple availability zones) has had cascading failures bringing down the entire region altogether. Depending upon the business criticality of the services that you are running in the cloud, that may or may not be an acceptable risk.
You have a desire to reduce service latency for your customers. This is especially true for global businesses where you’d like to make sure, for example, that your customers in Asia are not forced to go half way across the globe to retrieve an image from an S3 bucket in N. Virginia.
You have a desire for complete isolation between regions for the purposes of blue-green type deployments across regions. For example, you would like to limit the availability of a modified API Gateway end point to a single region so as to monitor and isolate failures to that single region.
Configuration
Our intent from this point on is to create a single set of terraform configs that we can then apply to multiple regions. To this end, we will define Terraform workspaces that map to individual regions, and refactor our resources (if needed) so that we don’t have namespace collision in AWS.
We’ll start by defining the configuration to reference the workspace name in our provider definition
provider"aws"{region="${terraform.workspace}"}
Note that once this config is added, terraform init will no longer work in the default workspace, since (as you may have guessed) there is no default region for AWS. However, if we were to create a workspace corresponding to a valid AWS region and then terraform init, that would work
shanid:~/dev$terraform workspace new us-east-1
Created and switched to workspace "us-east-1"!
You are now on a new, empty workspace. Workspaces isolate their state,
so if you run "terraform plan" Terraform will not see any existing state
for this configuration.
Once the workspace is created, we should be able to run terraform init, terraform plan and terraform apply as usual.
Once we have provisioned our resources in this region, create a workspace for a second region and re-run the terraform in that workspace to create the exact same set of AWS resources in that region.
shanid:~/dev$terraform workspace new us-west-2
Created and switched to workspace "us-west-2"!
You are now on a new, empty workspace. Workspaces isolate their state,
so if you run "terraform plan" Terraform will not see any existing state
for this configuration.
The only (minor) gotcha to look out for is with regards to AWS resources that are global or globally named. IAM is an example of a global resource, and S3 is an example of a resource that has a globally scoped name. Consider the following example,
If we were to attempt to create this resource in multiple resources, we’d start running into issues. This would work just fine in the first region, but in subsequent regions, you’d start seeing errors when applying your terraform since the resource my_lambda_role already exists. The easiest way to solve for this, is to include the region/workspace in the name of the resource being created. For example, the following config will create distinctly named IAM roles
This would create a my_lambda_role_us-east-1 role in us-east-1 and a my_lambda_role_us-west-2 role in us-west-2. And we have maintained our objective of a single configuration that can be deployed seamlessly into multiple regions.
Conclusion
Hopefully this approach makes it easier for you to manage your cross-region deployments much more easily with Terraform. I should acknowledge that using workspaces is probably not the only way to go about solving for this problem, but this is the way that we’ve solved for most of our deployment related challenges with the least possible amount of repetition in our configs.
As always, please feel free to leave a comment if you’re having issues with the sample config or if you’re running into issues that I have not covered in this post.
…
In real world production systems, we’re always forced to concede that systems inevitably fail and we always should have our tooling ready to help us detect and fix issues as soon as they occur. We have to do this before minor issues start cascading to broader issues that start impacting our customers or our bottom lines. Having reliable log data and the ability to parse through and inspect thousands/millions of log lines in near real time can make or break our troubleshooting efforts.
For web applications that are delivered on the Akamai platform, a lot of the information for troubleshooting and, more generally, understanding traffic patterns and trends is available for us on the Luna portal. However, if we need a slightly more granular analysis of the data or a closer-to-real-time feel of the data, Akamai’s CloudMonitor feature is the way to go. CloudMonitor does have native support for enterrpise scale analysis tools like Splunk and SumoLogic, but if you’re looking for an easy and relatively cheap way to start looking at the data, Amazon Web Services (AWS) has a few services that’ll help you get going.
In this blog post, I’ll try to focus more on the data ingest part of this equation and less on the Akamai property configs needed to set this up. Akamai professional services and/or the CloudMonitor product documentation can help with the latter.
Integration Approach
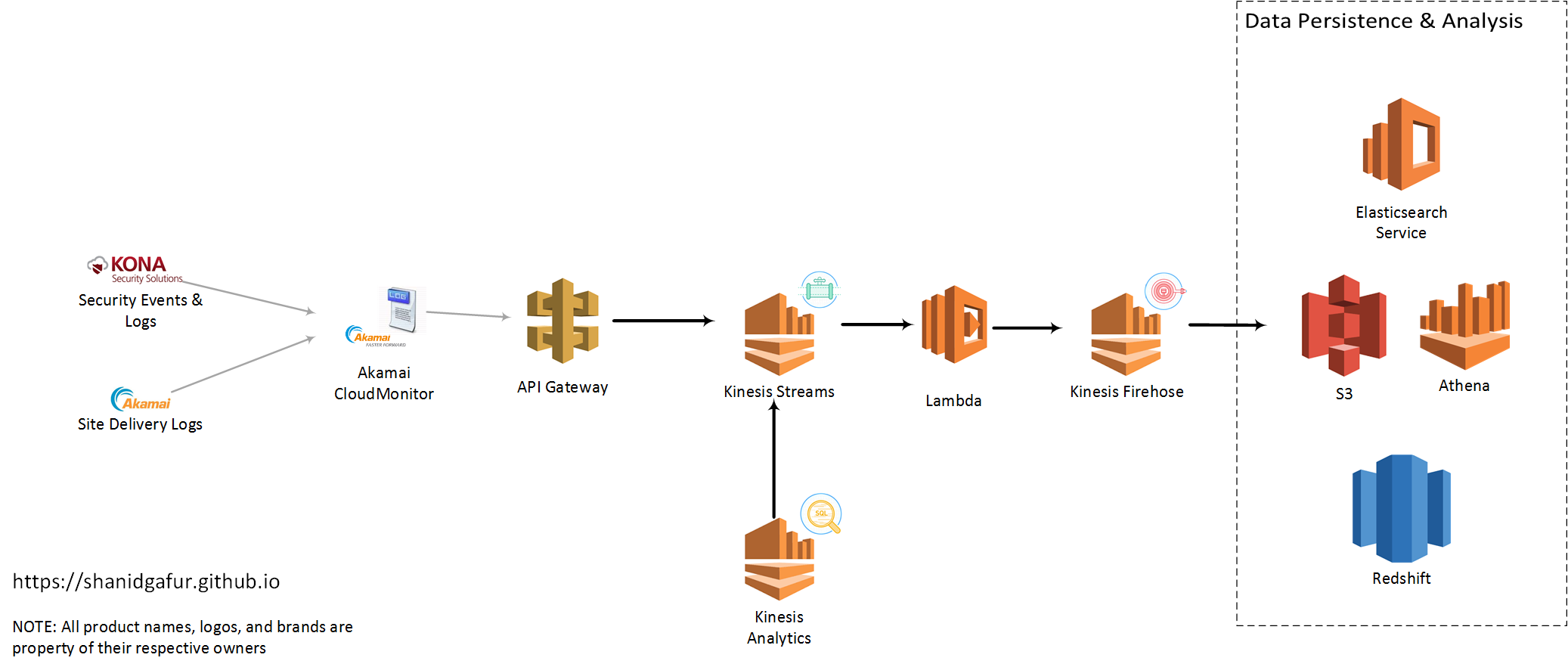
There are a few distinct services that I had used to scale up my implementation to a state that I felt comfortable. Some of these may become more or less pertinent for your use case depending on factors like traffic to your site (the more visitors you have, the more log lines that need to flow over), data retention needs etc.
API Gateway:
The configuration for CloudMonitor delivery config in Akamai requires specifies am API end point that accepts HTTP POST requests. AWS API Gateway gives us an easy way to setup such an end point for CloudMonitor. For high traffic sites, expect to have a significant hits per second ratio. So as to not introduce any latency to the end point, it is very important for the API to do as minimal as possible to capture the payload and respond back with a 200 OK status code. The easiest way to accomplish this is to have the API write the payload as such to queue or topic based messaging middleware. This is where AWS Kinesis Streams comes in. API Gateway can be used to map the incoming request to Kinesis Streams (or any other AWS service, for that matter) relatively easily.
In order to map the incoming payload to a Kinesis message, create a body mapping template for Content-Type application/json with the following configuration
In plain english, this configuration takes the HTTP POST body, base-64 encodes it and writes to a Kinesis Stream called CloudMonitorStream. Additionally, it uses the IP address of the client calling it as the partition key for sharding the data into of many partitions of the CloudMonitorStream.
Kinesis Streams:
AWS Kinesis Streams gives us the ability to ingest large amounts of data and durably store that data while process the payload. The only real configuration needed for the Stream is to define the number of shards or partitions for the data. From the AWS documentation,
Lambda: Now that we’ve gotten to a state where we can accept the payload and temporarily store it for processing, it’s time for the actual data processing to begin. This is where AWS Lambda comes into play. Lambda, if you haven’t used it yet, is the AWS implementation of the broader trend usually refered to as serverless computing. Lambda allows us to write code in our language of choice (currently support Java, Python, node.js and C#), and have that code get triggered automatically in response to events raised outside of that code.
The code that get triggered can be used to do pretty much anything that that the runtime language supports. For this use case, I used Lambda to strip out some characters in the payload that were making life difficult downstream in ElasticSearch. I also modified the latitutde and longitude data in my CloudMonitor payload to look more like an ElasticSearch geo_point data type. Code snippet below to give you an idea of what I mean by this.
Once we have the data payload formatted and modified, we can write out this formatted json object into my Kinesis Firehose instance.
Kinesis Firehose:
Although, they’re both branded “Kinesis” by AWS, the function of Kinesis Firehose is slightly different from the function of Kinesis Streams. The objective with using Kinesis Firehose is to transfer data from a source to a defined data sink like S3, ElasticSearch Service or Redshift. Firehose helps manage logic for retry, failures etc for the data that is flowing through it. Configuration for Firehose instances are quite painless and very easy to manage.
With the help of Firehose, we should be able to write data into one of the supported data sinks where we can subsequently analyze and visualize the data from CloudMonitor to our hearts content!
Image: HTTP Response codes over time
Conclusion
By putting together the AWS services highlighted above, we’ve created a solution to ingest large volumes of log data from Akamai CloudMonitor to a data store that we can use for data discovery and analysis. While this blog post talks about this approach in the context of Akamai, these AWS services could really be used for ingest and processing of any large stream of data.
If you need additional details about any aspect of this integration, or if you have alternate approaches that you’d like to share, please post a comment below.
…
In my last post on Apache Avro, I hinted at additional use cases for Avro serialzed data. In this post, I’d like to walk through serializing my data to an Apache Kafka topic.
For anyone who is not familiar with it yet, Apache Kafka is a high throughput, distributed, partitioned messaging system. Data is published to Kafka topics where it will become available for consumption by any number of consumers subscribing to the topic.
Solution Setup
One of the interesting things about the Kafka project, is that the implementation for Kafka clients (other than the default jvm client) is not maintained by the project. The idea is for outside implementers who are more familiar with their development platforms have greater velocity in developing clients. For .net itself, the project lists quite a few different external implementations. Unfortunately, not all these appeared to be in the same levels of completion and required a bit of poking around to figure things out. For the little project that I was looking at, we eventually decided to go with Microsoft’s implememtation called Kafkanet.
In order to use the Kafkanet client, start off by downloading the source code and building the solution. So as to make it easier to consume in my solution, I packaged up the binaries in a nuget package. The only dependency needed for this nuget package was the Apache Zookeeper .net client which is available on nuget.org. I’ve added my nuspec file below for reference, should you need it..
<?xml version="1.0" encoding="utf-8"?><packagexmlns="http://schemas.microsoft.com/packaging/2012/06/nuspec.xsd"><metadata><id>Microsoft.Kafkanet</id><version>0.0.58.1</version><title>KafkaNet.Library</title><authors>Microsoft</authors><projectUrl>https://github.com/Microsoft/Kafkanet</projectUrl><iconUrl>https://kafka.apache.org/images/kafka_logo.png</iconUrl><requireLicenseAcceptance>false</requireLicenseAcceptance><description>Build of Microsoft Kafkanet solution https://github.com/Microsoft/Kafkanet</description><dependencies><grouptargetFramework=".NETFramework4.5"><dependencyid="ZooKeeper.Net"version="3.4.6.2"/></group></dependencies></metadata><files><filesrc="lib\KafkaNET.Library.dll"target="lib\KafkaNET.Library.dll"/></files></package>
Sample code
Picking up where I left off the Avro serialization example, here’s some sample code that takes the data and pushes that over to a Kafka topic
//Connect to Kafka instance
varbrokerConfig=newBrokerConfiguration(){BrokerId=0,Host="kafka-dev-instance",Port=9092}varconfig=newProducerConfiguration(newList<BrokerConfiguration>{brokerConfig});//Create Avro serialized stream
varstream=newMemoryStream();Encoderencoder=newAvro.IO.BinaryEncoder(stream);varwriter=newAvro.Specific.SpecificWriter<Error>(newSpecificDefaultWriter(error.Schema));writer.Write(error,encoder);//Publish to Kafka
varmsg=newKafka.Client.Messages.Message(stream.ToArray());varproducerData=newProducerData<string,Kafka.Client.Messages.Message>("kafka-topicname",timestamp.value.ToString(),msg);using(varproducer=newProducer<string,Kafka.Client.Messages.Message>(config)){producer.Send(producerData);}
… and voila, you are now writing your Avro serilialized data into a Kafka topic. As you can see, the code is mostly straight forward but it did take a few hours of digging in to the code to get this right.
Hope this proves helpful to anyone else trying to do something similar. As always, feel free to leave a comment.
…
Recently, I had an opportunity to work a very interesting prototype using Apache Avro and Apache Kafka. For those of you who haven’t worked with it yet, Avro is a data serialization system that allows for rich data structures and promises an easy integration for use in many languages. Avro requires a schema to define the data being serialized. In other words, metadata about the data that is being serialized. If it helps, think of the Avro schema being akin to an XSD document for XML.
Avro does, in fact, have a C# library and code gen tools for generating POCOs from avro schema files. Unfortunately, not a whole lot of documentation exists for either. It took a quite a bit of trial and error to get my serialization logic nailed down. Hopefully this post will help others get started using Avro a lot more easily than I was able to..
Solution Setup
For the purpose of illustration, I’ve setup a fairly simplistic console app that will create an Avro serialized file stream. After creating the solution in Visual Studio, we start off by pulling in the Avro libraries. Fortunately, nuget.org does have nuget packages for Avro. The Avro package contains the core libraries and the Avro Tools package contains the code gen utility.
Avro Schemas & Code generation
The first step towards getting the serialization to work is to define the schema for the objects that I would like to serialize. In my hypothetical example, I’d like to define a schema for capturing Errors as they occur in a web application and serializing those to a Kafka based system. (We’ll focus on the Avro part for now, and leave the Kafka bits for later).
{"type":"record","name":"Error","namespace":"com.shanidgafur.error","doc":"This is an error record for my application","fields":[{"name":"id","doc":"System-generated numeric ID","type":"int"},{"name":"appname","doc":"The name of the application generating the error","type":"string"},{"name":"details","doc":"Details of the error","type":"com.shanidgafur.error.ErrorDetails"}]}
As you can see, I have three fields in my record - an id, the name of the application that generated the error and a complex type called details. The description for my complex type looks like this.
{"type":"record","name":"ErrorDetails","namespace":"com.shanidgafur.error","doc":"This is an error details record","fields":[{"name":"category","doc":"Category of the error. Eg: DatabaseConnectionError","type":"string"},{"name":"severity","doc":"The severity of the error. Eg: CRITICAL, FATAL, WARNING","type":"string"},{"name":"timestamp","doc":"Timestamp (UNIX epoch) of error","type":"long"}]}
The next step would be to generate the C# code using these schemas. This, unfortunately, is where we enter into completely undocumented feature space. Assuming you’ve added the Avro Tools package to your solution, the codegen utility (codegen.exe) will exist inside the packages\Apache.Avro.Tools.1.7.7.4\lib folder. I tried a number of different ways to get the code generation to work across multiple schema files, but did not have a whole lot of success getting the utility to work.
In the end, I had to copy avrogen.exe, Avro.dll (from the Avro package lib directory) and Newtonsoft.Json.dll into a folder along with the avsc file to get this to work. Additionally, I have to merge the two schema types into a single file. A bit of cop out, I’ll admit, and one of these days I plan to get back to figuring out if there is a better way to do this.
In the end, this is what my merged schema file looked like
{"namespace":"com.shanidgafur","type":[{"type":"record","name":"ErrorDetails","namespace":"com.shanidgafur.error","doc":"This is an error details record","fields":[{"name":"category","doc":"Category of the error. Eg: DatabaseConnectionError","type":"string"},{"name":"severity","doc":"The severity of the error. Eg: FATAL, WARNING","type":"string"},{"name":"timestamp","doc":"Timestamp (UNIX epoch) of error","type":"long"}]},{"type":"record","name":"Error","namespace":"com.shanidgafur.error","doc":"This is an error record for my application","fields":[{"name":"id","doc":"System-generated numeric ID","type":"int"},{"name":"appname","doc":"The name of the application generating the error","type":"string"},{"name":"details","doc":"The name of the application generating the error","type":"com.shanidgafur.error.ErrorDetails"}]}]}
Once I had all this squared away, the actual code generation part came down to a single command
avrogen.exe -s Error-Merged.avsc .
This generates two .cs files that I then just pulled into my solution.
Avro Serialization to disk
This was another area where there really wasn’t a whole lot of good sample code to explain the use of the library. Ended up looking at usage of the Java library to figure this out.
//Calculate Epoch Timestamp
DateTimeEpochBeginDate=newDateTime(1970,1,1);longCurrentTimestamp=(long)(DateTime.Now.ToUniversalTime()-EpochBeginDate.ToUniversalTime()).TotalSeconds;//Populate the code generated Avro POCOs with data to be serialized
ErrorDetailsdetails=newErrorDetails{Category="DBConnectivity",Severity="FATAL",Timestamp=CurrentTimestamp};Errorapperror=newError{Details=details,Appname="MyApplication",Id=123};//Setup File Stream for serialization
stringfilelocation=@"c:\temp\avro.bin";varstream=newFileStream(filelocation,FileMode.OpenOrCreate,FileAccess.ReadWrite,FileShare.Write);//Endode the stream and write to file system
Avro.IO.Encoderencoder=newBinaryEncoder(stream);SpecificDefaultWriterwriter=newAvro.Specific.SpecificDefaultWriter(apperror.Schema);writer.Write<Error>(apperror,encoder);stream.Close();
Build and run this code to get the serialized data written to disk. While this may not seem as much, we should consider that once we get the Avro serialization taken care of, the data can be streamed not only to the file system but across the wire as well.
Conclusion
Hopefully, this post helps someone get a head start into using Avro on the .net platform. For anyone who’s interested, the full solution is available here. Please feel free to fork and add more useful bits to the code.
I should point out that I, myself, am very new to Avro and am still learning the nuances that go with the framework. If you have a helpful hint or tip, please do leave a comment..
…
Since setting up this blog, I’ve been tweaking away little things to make them ever so slightly better. Integrating web analytics, diqus comments integration etc etc. One of the things that I’ve been meaning to do but did not get really get around to was changing the look and feel of the default jekyll site.
Jekyll themes FTW
In case you haven’t already checked it out, head on over to the jekyll themes site to check out the wide range of possibilities. The gallery of themes is pretty darn impressive and it’s hard not to find at least a few that you like. I finally settled on a nice minimalistic theme by Josh Gerdes.
Before
After
Knowing me, I’m probably not even close to done tinkering with this site. Continuing to enjoy jekyll and the ecosystem of plugins, themes etc that are supported. Have a suggestion for tweaking things further? A plugin that you’d like to recommend, perhaps? Add a note in the comments section below…
…
Since this is the very first post on this blog, and I am not sure how many posts will follow this one, I’ve decided to start off by just explaining how this blog has been setup and how you, too, can have your very own shiny new blog on github pages.
For what it’s worth, I’ve discovered there’s quite a few blog posts out there that talk through all of the steps outlined below, in quite a bit more detail. You can consider this the TL;DR version of those posts.
Domain Setup: Github.io
This is super straight forward, and there’s really nothing more that I can add to the documentation from Github Pages.
Jekyll Installation
This is my first time using Jekyll and I have to say that I’m really impressed by the sheer simplicity and ease of use.
As a windows user, setting up my local blogging environment came down to the following few steps
(If you don’t already have this..) Install chocolatey. In a powershell window, run the following command
The setup and customization of your blog is where you will really start to get to know jekyll. Start off first by creating you new blog
jekyll new myblog
What this will do will create a folder structure similar to the below
Right off the bat, you can run this sample site to see what the blog looks like by running the following comand
jekyll serve
This will start off a running instance of the generated html for the site, and you will be able to see this at http://localhost:4000/
To see draft posts
jekyll serve --drafts
At a high level, the _layouts folder contains (as expected) the overall layouts of the site. The layouts themselves are mostly html with a bit of liquid tags mixed in. Layouts themselves mostly serve as placeholders for html includes that exist in the _includes folder. With these two building blocks in place, changing the look and feel of the site boils down to one of two things
To change the overall organization of the page, tweak the layout.
To add additional snippets of reusable html, javascript, css into the layout, create a new include file and reference that in the layout.
Creating a post
Blog posts and pages in general can be created using markdown or html. The only thing the page really needs is the Front Matter block that specifies some attributes of the page like the layout to be used, tags on the page etc. For example, here’s the Front Matter block for this page.
---
layout: post
title: "Setting up this blog"
summary: This post talks about the process followed to setup a blog on github pages using jekyll
tags: [jekyll,blogging,github pages, discus]
---
You can create pages in the _drafts folder and review the page using the jekyll serve --drafts command mentioned above.
Once you’re good with the way the page looks, you can copy the draft to the _posts folder. Remember that posts need to use the following naming convention YEAR-MONTH-DAY-title.MARKUP
Publishing
All you really need to do is use the following command
jekyll build --destination <destination>
Check the output of the build to the repo for github page, and voila you’re done!
Hopefully this guide helps you along as your way as you attempt to start your own experiments with Jekyll. If you’ve found this useful or have some additional tips for jekyll users, please leave me a comment or hit me up on twitter.
Cheers!
…
 There are a few distinct services that I had used to scale up my implementation to a state that I felt comfortable. Some of these may become more or less pertinent for your use case depending on factors like traffic to your site (the more visitors you have, the more log lines that need to flow over), data retention needs etc.
API Gateway:
The configuration for CloudMonitor delivery config in Akamai requires specifies am API end point that accepts
There are a few distinct services that I had used to scale up my implementation to a state that I felt comfortable. Some of these may become more or less pertinent for your use case depending on factors like traffic to your site (the more visitors you have, the more log lines that need to flow over), data retention needs etc.
API Gateway:
The configuration for CloudMonitor delivery config in Akamai requires specifies am API end point that accepts 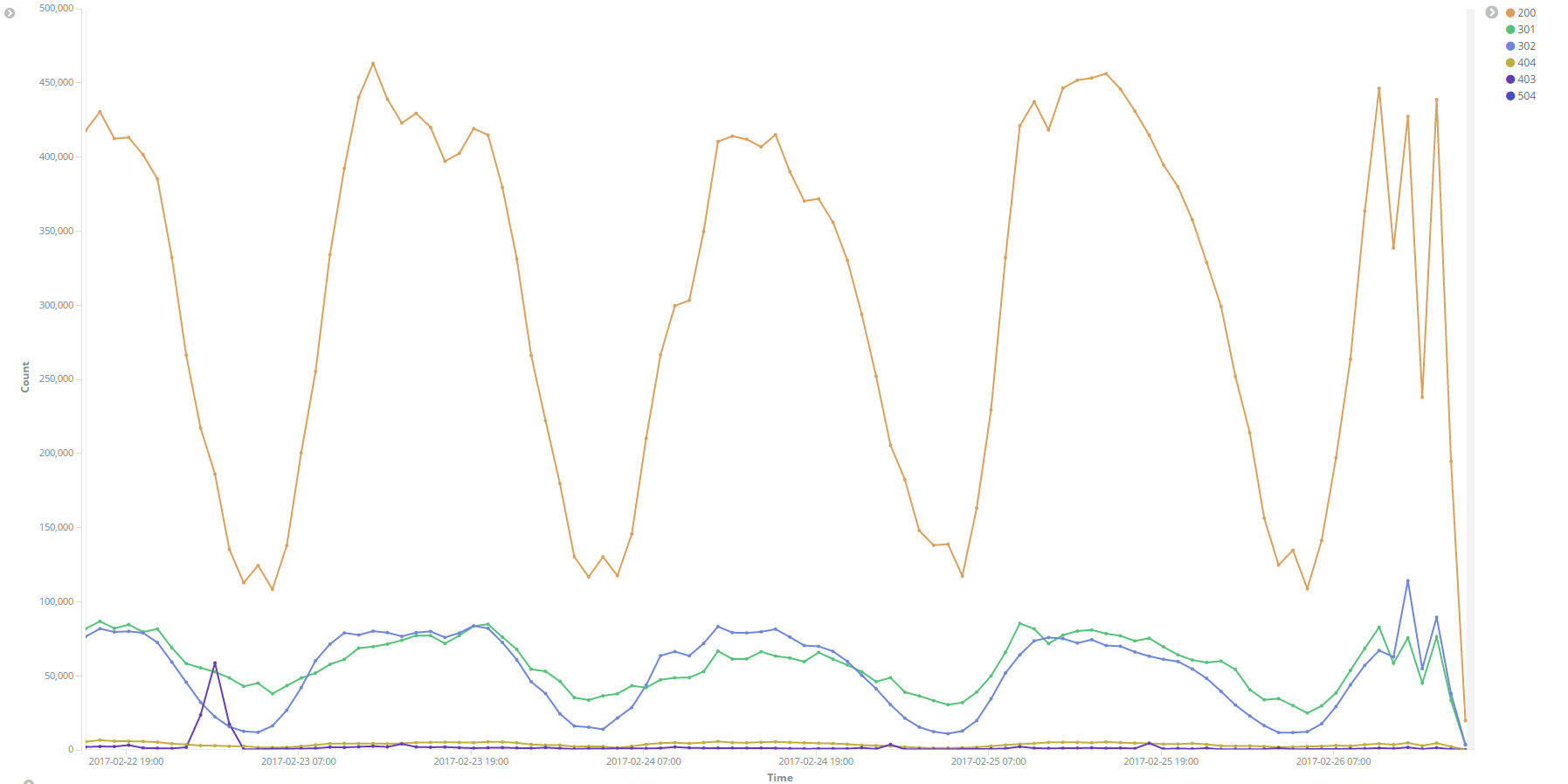 Image: HTTP Response codes over time
Image: HTTP Response codes over time
 Knowing me, I’m probably not even close to done tinkering with this site. Continuing to enjoy jekyll and the ecosystem of plugins, themes etc that are supported. Have a suggestion for tweaking things further? A plugin that you’d like to recommend, perhaps? Add a note in the comments section below…
…
Knowing me, I’m probably not even close to done tinkering with this site. Continuing to enjoy jekyll and the ecosystem of plugins, themes etc that are supported. Have a suggestion for tweaking things further? A plugin that you’d like to recommend, perhaps? Add a note in the comments section below…
…
